
.svg)






Big Data
Готовая платформа для работы с большими данными — все преимущества аналитики больших данных с меньшими затратами сил, времени и средств
Компоненты комплексного проекта

ELT-фреймворк
Приложение для извлечения данных из различных источников, загрузки в облачное корпоративное хранилище и приведения к единому формату для всех пользователей. ELT-фреймворк предназначен для работы с хранилищами данных Greenplum. Позволяет настраивать правила и автоматизировать формирование кода для загрузки.
- Унификация методов работы с данными
- Контроль нагрузки на кластер, журналирование и мониторинг загрузки
- Добавление новых таблиц/источников и управление загрузкой
- Различные методы извлечения данных из источника и обновления данных в хранилище. Возможность загрузки через брокер: установка агентов в источниках для безопасного извлечения корпоративных данных

Arenadata DB
Аналитическая распределенная СУБД, построенная на MPP-системе с открытым кодом Greenplum. Предназначена для хранения и обработки больших объемов информации — до десятков петабайт.
- Cкоринг
- Глубокий ad-hoc анализ
- Эффективное соединение больших таблиц
- Сложные запросы обработки больших данных/сложная аналитика (включая аналитику поведения пользователей)
- Предсказательная аналитика (спрос, остатки)
- Cистемы маркетинговых кампаний, системы лояльности
- Любые типы отчетности (операционная, управленческая, обязательная регуляторная)

BI
Система глубокой аналитики и визуализации данных, представление данных в удобном для восприятия виде для принятия управленческих решений. Реализована на базе платформы Visiology и решения с открытым кодом Superset.
- Язык запросов DAX – полный аналог Power BI
- Модуль анализа и прогнозирования
- Smart Forms: сбор и визуализация разнородных данных, в том числе введенных вручную тысячами пользователей
- Мобильное приложение в AppStore и Google Play
- Рассылки регламентных отчетов любой сложности на основе шаблонов Excel. Виртуальный аналитик, понимающий естественную речь на русском языке
- Кастомизация и повторное использование виджетов на уровне JavaScript. Качественная интеграция с Python без замены UI-слоя для выполнения ML-моделей
Ключевые возможности

Быстрый старт проекта
Запуск проекта больших данных без значительных начальных вложений в оборудование. Быстрое последующее масштабирование платформы с оплатой за фактически использованные ресурсы.

Ускорение принятия решений
Многократное увеличение скорости создания аналитических отчетов и принятия бизнес-решений на основе данных.
Быстрая проверка гипотез
Проверка гипотез и оптимизация бизнес-процессов в течение 2 недель после запуска проекта.

Оптимизация бизнеса
Финансовая выгода от оптимизации бизнеса на основе анализа больших данных до 60% по опыту реализованных проектов.

Экономия на обслуживании
Освобождение ИТ-персонала от рутинных задач за счет привлечения компетенций провайдера, при этом затраты на обслуживание сокращаются до 3 раз.
Строгий SLA
Обеспечение доступности платформы и инфраструктуры для больших данных на уровне 99,95% и оперативное реагирование на инциденты в течение 10 мин в соответствии со строгим SLA.
Сценарии использования
В банках:
- Прогнозирование ухода клиентов и предотвращение их оттока
- Прогноз необходимого остатка наличных средств в кассах и банкоматах с точностью до 99,6%
- Рекомендации наилучших действий (next best action) сотрудникам фронт-офиса и операторам контакт-центра для роста продаж
- Противодействие мошенничеству — выявление рисков противозаконных транзакций
В промышленности:
- Прогнозирование, выявление причин и предотвращение брака на технологическом конвейере
- Мониторинг износа и амортизации оборудования (ТОИР) для экономии на обслуживании
- Оптимизация расхода дорогостоящего сырья
- Разведка залежей сырьевых ресурсов по анализу данных спутниковой и аэрофотосъемки. Оптимизация и сокращение затрат на добычу
В ритейле:
- Формирование ассортиментной матрицы и оптимизация товарных остатков
- Товарные рекомендации по анализу чека и истории покупок
- Анализ поведения клиентов на сайте в реальном времени и спасение «брошенных» корзин
- Персонализация коммуникации с пользователями во всех каналах
- Составление рейтингов поставщиков
На транспорте и в логистике
- Регулирование тарифов с учетом состояния транспортного парка, расхода на топливо и заявок клиентов
- Снижение аварийности за счет анализа данных телеметрии автомобилей
- Управление расписанием движения транспортных средств
Как мы работаем





Часто задаваемые вопросы
Как монетизировать имеющиеся данные?
Данные не зря называют новой нефтью — с их помощью можно значительно повысить эффективность бизнес-процессов компании.
Например, в промышленности с помощью решений промышленной аналитики можно исследовать эффективность технологического процесса в целом или производственного процесса конкретного подразделения. Поскольку источников данных, например, цехов очень много, часто необходима именно аналитика больших данных, что позволяет изучить и проанализировать производственный процесс с разных сторон.
В банках все чаще большие данные используются, чтобы предлагать банковские продукты потенциальным клиентам. В ритейле большие данные используются для формирования ассортиментной матрицы и прочих предложений.
Чем озера данных отличаются от больших данных?
Озера данных — это составляющая часть больших данных. Они предназначены для сбора разнородной информации — структурированной или неструктурированной. В случае неструктурированных данных зачастую нет возможности разобраться в их структуре до сохранения. Поэтому важным отличием озер данных является изменение парадигмы работы с данными: сначала данные сохраняются, а потом с ними начинают разбираться. Таким образом, озера данных позволяют «сохранить на будущее» полученные данные, а уже потом понять, как их использовать и интегрировать из озер в инфраструктуру.
Чем озера данных отличаются от хранилищ данных?
В озера данных сохраняются любые наборы данных, которые могут дублироваться, и единая «версия правды» создается уже после сохранения. В хранилище же изначально сохраняется структурированная информация без дублей и с самого начала существует единая «версия правды».
Кроме того, хранилища создаются в соответствии с регламентными процессами, и информация в них поступает только из проверенных источников, которые контролирует ИТ-служба предприятия. Сохранить же информацию в озере данных, обработать ее и подготовить витрины может фактически любой сотрудник, у которого есть на это право.
Суммируя, разница заключается в типах данных, видах нагрузки, применении, паттернах работы и вовлечении пользователей в процесс обработки данных.
На предприятиях часто используются различные системы для сбора и обработки данных. Нужно ли их унифицировать, прежде чем внедрять платформу для работы с большими данными?
Унификация данных — классическая задача. Реализация проектов в области больших данных часто начинается с консолидации данных на единой аналитической платформе. Один и тот же объект может быть по-разному представлен в разных учетных системах, и сопутствующая типовая задача в рамках проектов в области больших данных часто заключается в унификации такого объекта, т. е. приведении его к единому целевому формату. Для этого, в зависимости от степени интеграции существующих систем и используемых форматов данных, могут применяться различные инструменты.
Что собой представляет платформа для работы с большими данными?
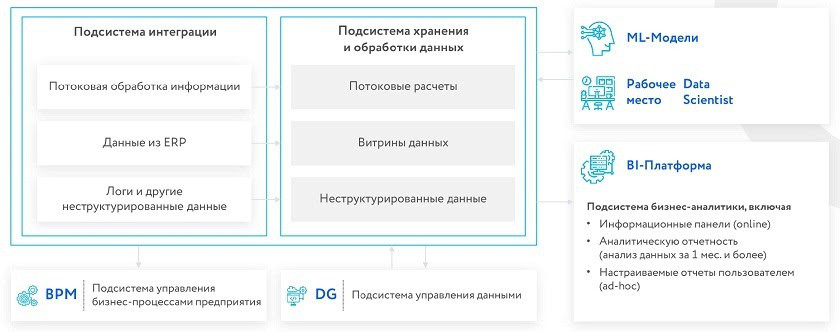
Функциональная архитектура платформы включает две ключевые подсистемы — подсистему интеграции для сбора и загрузки данных, их потоковой и пакетной обработки, и подсистему хранения и обработки данных, в которой выделяются различные слои хранения.
Платформа также включает BI-платформу для создания аналитической отчетности и пользовательских отчетов, математических моделей и т. д. На базе платформы может быть организована лаборатория данных, в которой пользователям выделяются определенные ресурсы и полномочия для работы с данными и проверки гипотезы, в том числе с использованием Python.
Вместе с платформой также внедряется подсистема управления данными класса Data Governance. Они обеспечивает прозрачность источников и процессов получения данных, преобразования данных перед использованием в витринах, что улучшает осведомленность пользователей и создает объективную картину данных. К платформе можно подключать различные системы, например подсистему управления бизнес-процессами (BPM).


Сопутствующие услуги







23
мая
16:00
16:00
Онлайн-митап
Онлайн-митап
18
апреля
16:00
16:00
Онлайн-митап
Онлайн-митап
4
апреля
18:00
18:00
Онлайн-дискуссия
Онлайн-дискуссия
Остались вопросы?
Заполните форму, и эксперт КРОК Облачные сервисы оперативно ответит на все ваши вопросы
КРОК Облачные сервисы
КРОК Облачные сервисы — это самостоятельное подразделение компании КРОК, предлагающее рынку облачные услуги и управляемые В2В-сервисы.
SLA 99,95
Время реакции 10 минут
с 2009
на рынке облачных услуг
800+
клиентов из разных отраслей
>400
экспертов реализуют проекты любой сложности